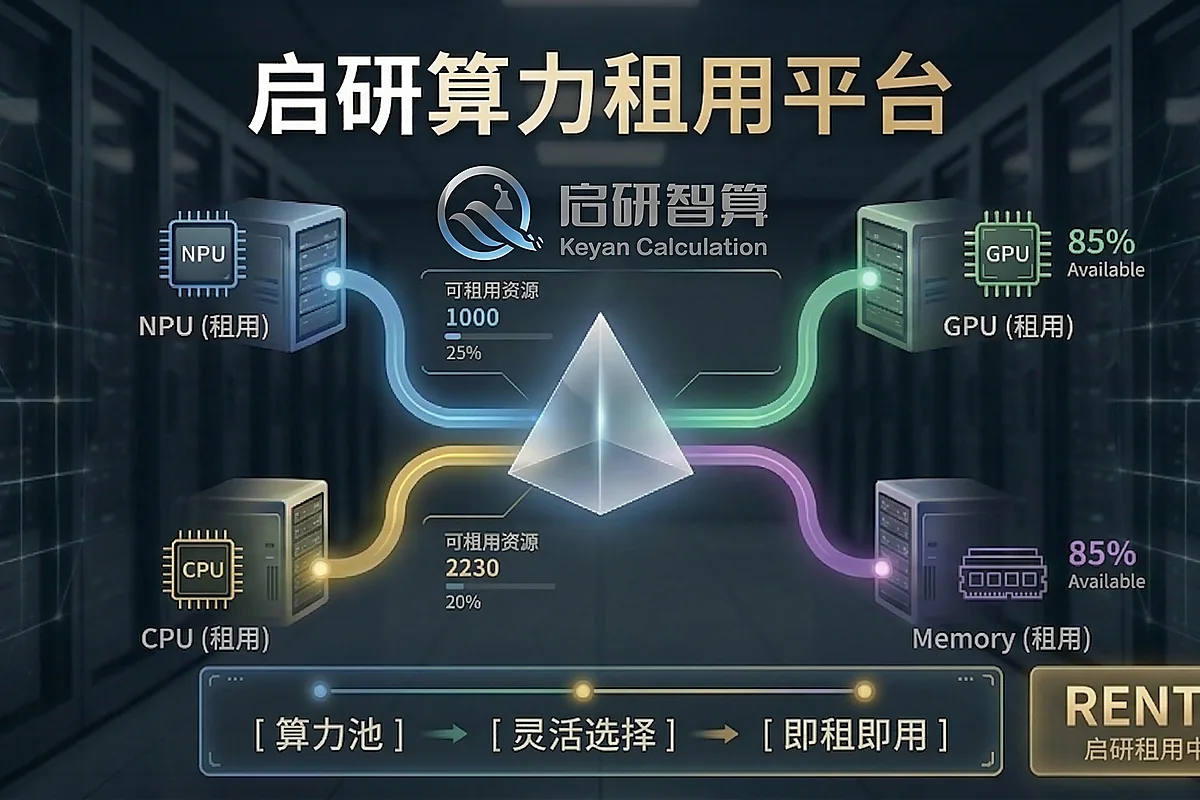

SERVICE PORTFOLIO
算力不是单一资源,而是一套可交付的服务矩阵
从短期租赁到平台化调度,栏目内容按行业站方式展开,方便用户理解“能用什么、怎么用、适合什么任务”。

SERVICE ROUTE
先判断使用路径,再落到资源规格
算力需求通常不是单选题:短期任务适合租用,团队协作适合平台化调度,长期硬件建设则进入独立的硬件定制页。

SELECTION GUIDE
按任务信号快速缩小选型范围
RESOURCE SPECIFICATION
可选算力资源参数
资源规格按 CPU、国产算力和 GPU 集群拆分展示,便于用户快速比较核心数、内存、显存和互联网络。
CPU 算力
适合 VASP、Gaussian、LAMMPS、有限元求解、批量参数扫描等 CPU 密集型科研计算任务。
国产算力(华为 Atlas)
适合国产化 AI 推理训练、昇腾生态适配和信创环境下的模型任务验证。
GPU 算力集群
适合深度学习训练、推理服务、可视化渲染和 GPU 加速仿真任务。
PLATFORM CAPABILITY
把算力、环境、调度和交付组织成一套平台能力
算力池化与弹性租赁
CPU、GPU、国产 NPU 资源按任务类型组合,支持短期扩容、批量计算和按需开通。
AI 调度平台
覆盖资源监控、模型开发、训练编排、数据集管理、模型服务、镜像仓库和操作审计。
科研软件环境
面向材料模拟、分子动力学、有限元、AI 训练等任务准备镜像、依赖和运行模板。
高速互联与数据流转
按资源类型接入 RoCE / IB 网络,支持大规模训练、轨迹文件和仿真结果的高吞吐读写。
集群建设与硬件定制
围绕 AI 训推一体机、塔式仿真工作站和实验室集群建设,衔接独立硬件定制页完成方案深化。
运维与安全审计
保留任务、资源、模型与代码操作记录;SLA、备份和权限策略待客户进一步确认。
PLATFORM PREVIEW
平台界面按实际使用流程展开
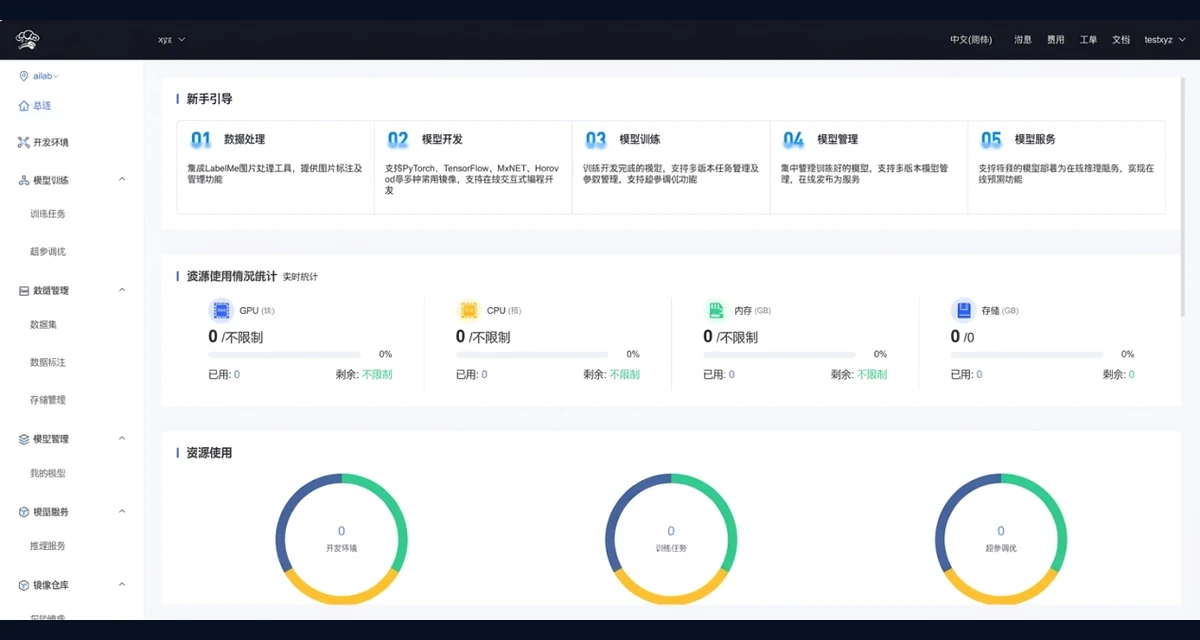
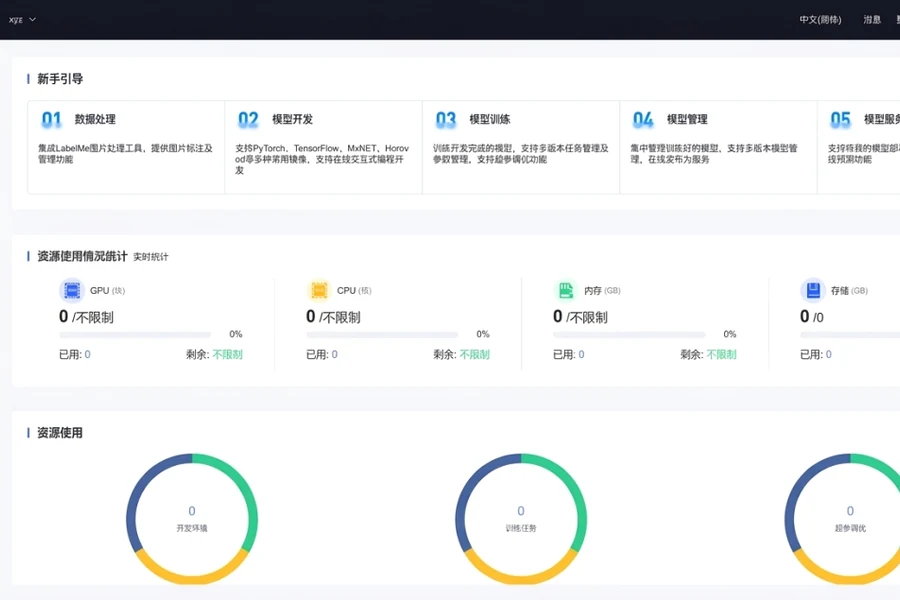
资源总览与新手引导
面向 GPU、CPU、内存、存储等资源使用情况提供总览入口,并串联数据处理、模型开发、训练、管理与服务。
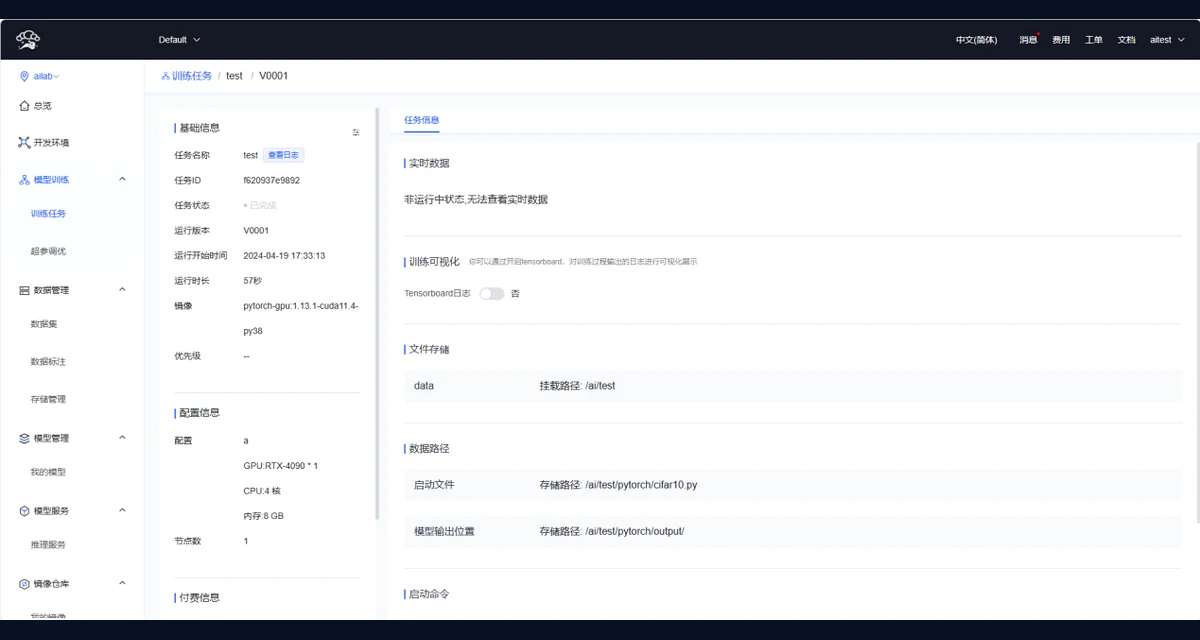
模型开发环境
支持 Notebook、镜像、任务模板和交互式开发流程,适合科研算法验证与模型调试。
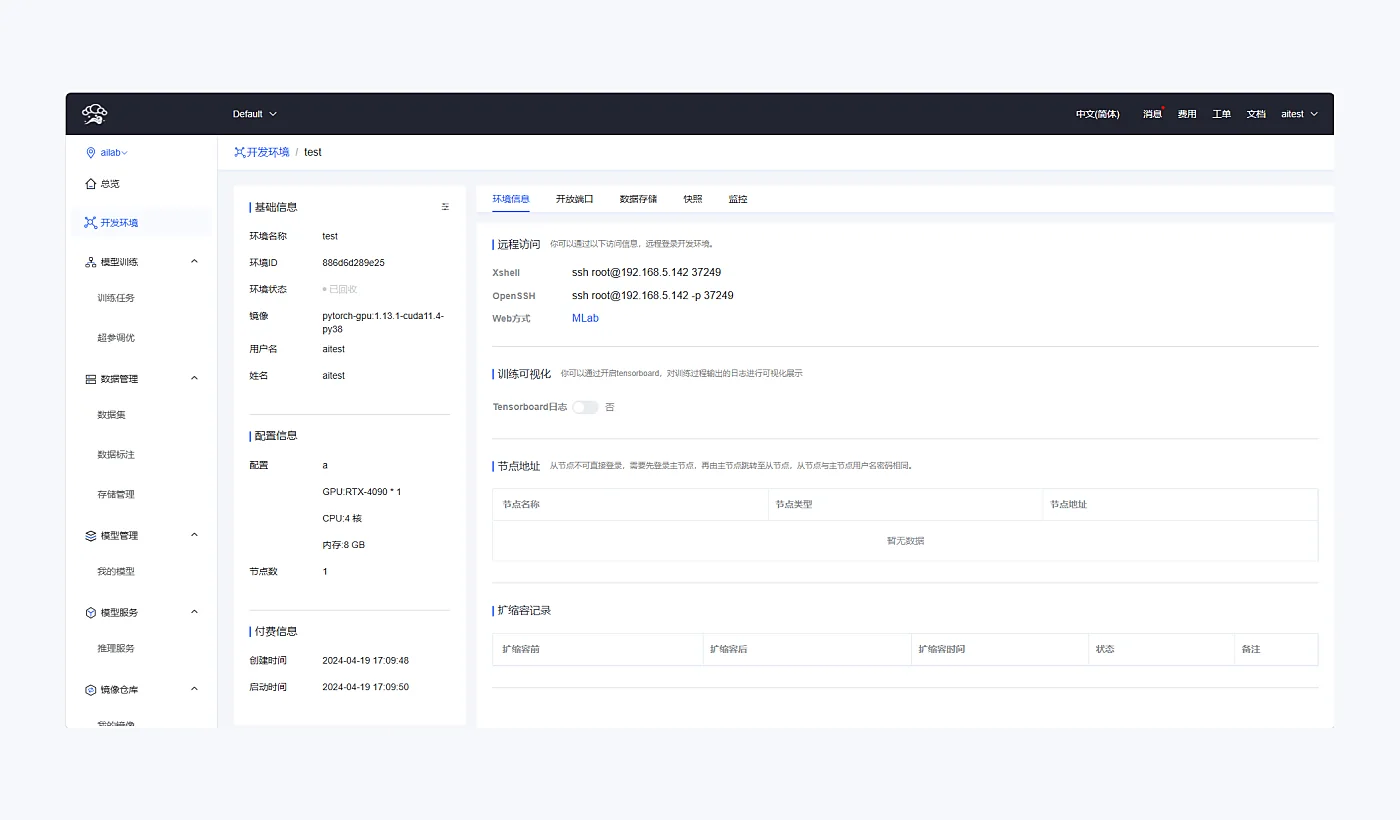
开发实例与远程访问
开发环境支持镜像、端口、数据存储、SSH / Web 访问和节点配置统一管理,方便多人按项目进入同一工作流。
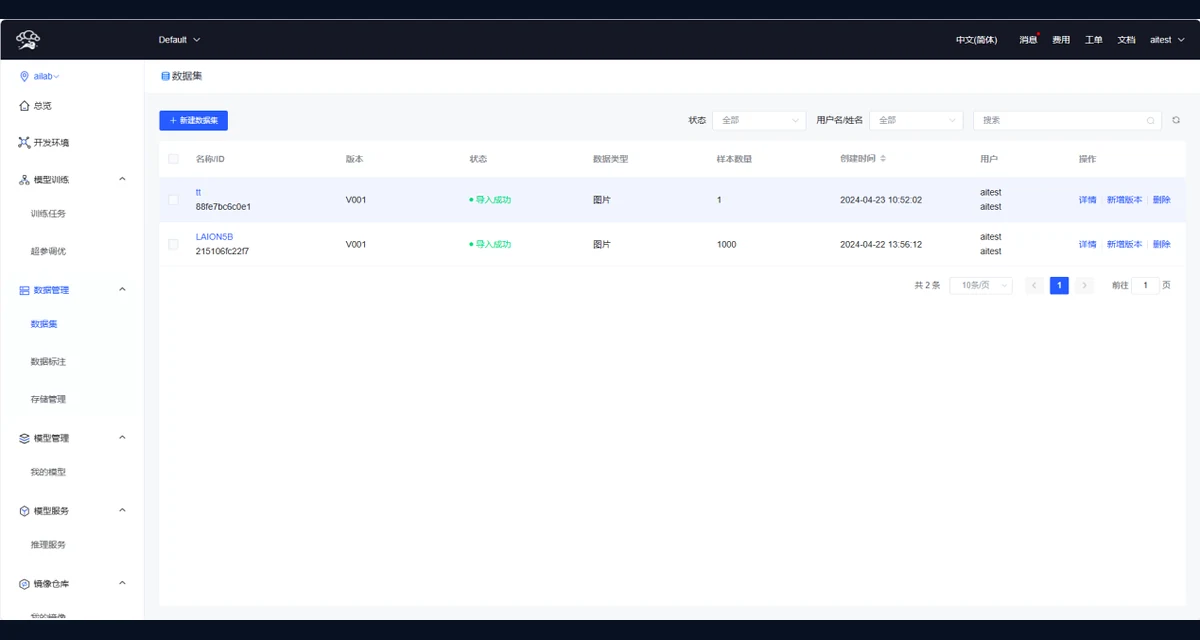
数据集与存储管理
集中管理数据集、数据标注、存储路径和任务输入,便于多项目、多人员协作。
PRIVATE HARDWARE
集群建设需要同时看性能、空间和扩展边界
服务器、塔式工作站、接口、供电、散热和应用场景会共同决定硬件路线;更完整的产品图、规格表和选型图进入硬件定制专题页。
进入硬件定制
扩展架构
处理器、内存、硬盘、网络、GPU 和电源能力集中展示,适合快速理解工作站扩展边界。

服务器规格总览
处理器、内存、硬盘、PCIe、网口、电源和系统支持集中呈现,便于在沟通阶段快速框定服务器能力。

工作站外观
塔式机箱更适合实验室、本地建模、前后处理和中小规模训练部署。

接口与面板
工作站后置接口、网络、USB、音频和顶部快捷接口影响日常接入、调试和本地设备协同。
DELIVERY PROCESS
从需求到结果交付,算力服务要有流程感
参考行业平台的表达方式,把“咨询后怎么推进”拆成清晰步骤,降低科研用户的决策成本。
-
01
需求评估
确认任务类型、软件栈、数据规模、并行方式和交付周期。
-
02
资源选型
在 CPU、GPU、国产 NPU 和平台资源中匹配合适配置。
-
03
环境准备
配置镜像、依赖、队列参数、访问方式和数据目录。
-
04
任务运行
提交作业、监控队列、跟踪资源利用率并处理异常。
-
05
结果交付
整理输出文件、日志、可视化结果和必要的复现实验说明。
-
06
长期运维
沉淀模板、镜像、数据规范和后续扩容建议。
FAQ
算力服务常见问题
围绕资源选择、使用路径和项目确认边界,先回答咨询前最容易卡住的问题。
CPU 节点、GPU 节点和 NPU 节点怎么选? +
CPU 更适合大量通用并行计算、批处理和部分传统仿真;GPU 更适合深度学习训练、GPU 加速求解和可视化;NPU 通常用于国产化 AI 训练、推理或适配验证。具体选择需要看软件和任务规模。
显存不够时一定要增加 GPU 卡数吗? +
不一定。显存不足可能需要降低 batch、使用混合精度、模型切分或更换更大显存卡。增加卡数是否有效取决于训练方式、互联网络和代码并行能力。
资源规格表里的配置是否代表实时库存? +
资源规格表用于说明可评估的资源类型和配置口径,不等同于实时库存、排队策略或固定交付时间。正式使用前仍需结合任务和当前资源安排确认。
AI 训练任务需要提前准备什么? +
建议准备模型框架、训练脚本、数据规模、预期显存、运行方式和目标结果。如果已有日志或历史运行配置,也可以一起提供,便于判断瓶颈。
私有化服务器选型为什么要看散热和电源? +
多 GPU 服务器长期高负载运行时,散热、电源、机箱空间和噪声会直接影响稳定性。只按显卡型号选型容易忽略整机约束。
能否支持国产算力适配? +
可以先评估国产算力适配路径。需要确认模型框架、算子支持、数据格式、目标硬件和推理或训练目标。是否能迁移以及工作量需要按项目验证。
READY TO START
带着任务类型和数据规模来,我们帮你匹配算力与交付路径
固定 SLA、价格、排队策略和账号权限会在咨询后按任务规模确认,避免用统一口径误导不同项目。