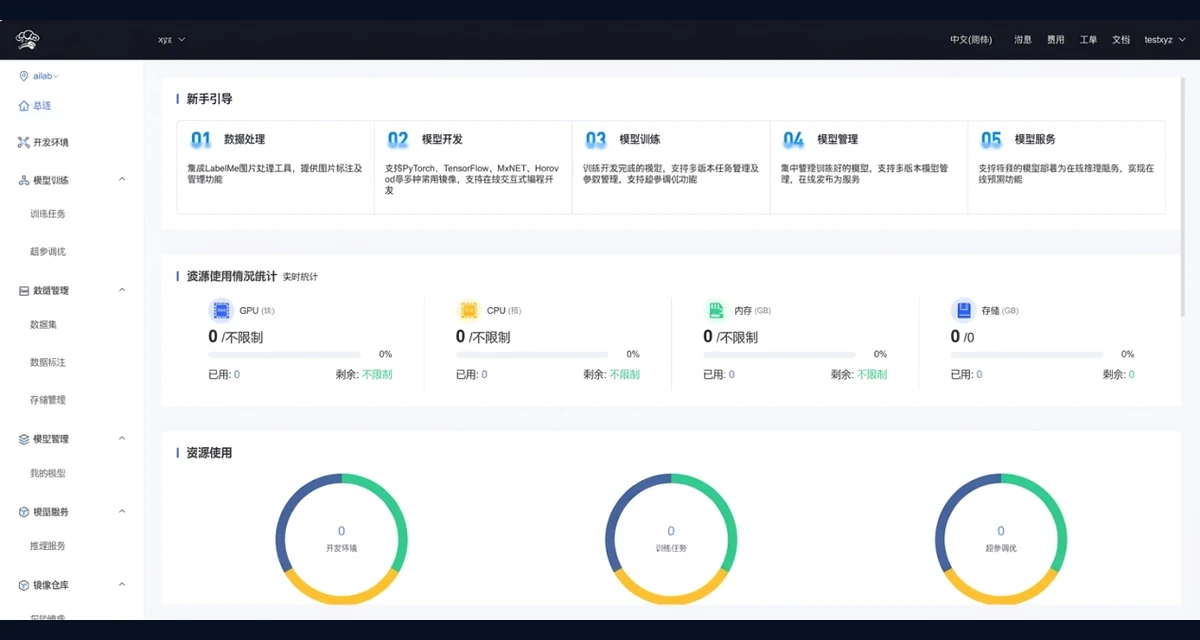
资源总览与新手引导
面向 GPU、CPU、内存、存储等资源使用情况提供总览入口,并串联数据处理、模型开发、训练、管理与服务。

数据集接入、清洗、标注与存储路径管理。
Notebook、镜像环境、交互式开发与多框架实验。
训练任务、队列调度、资源用量监控和超参调优。
模型版本、评估记录和发布前资产管理。
在线推理服务部署、服务状态查看和后续运维。
用户操作、代码仓、镜像、任务和服务行为留痕。
面向 GPU、CPU、内存、存储等资源使用情况提供总览入口,并串联数据处理、模型开发、训练、管理与服务。
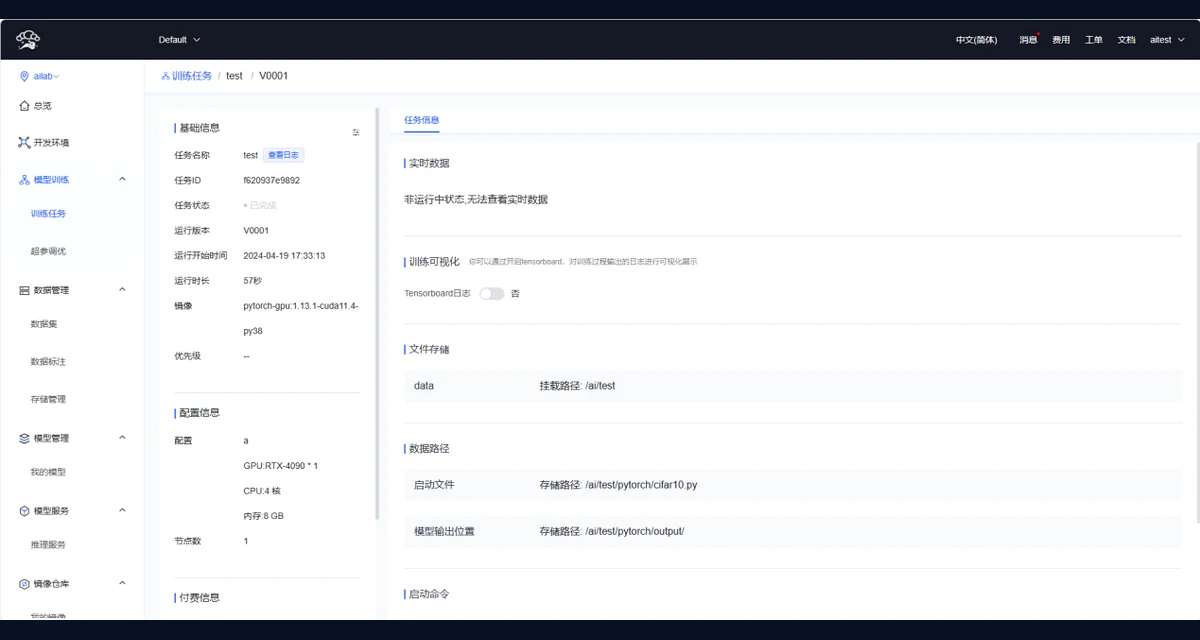
支持 Notebook、镜像、任务模板和交互式开发流程,适合科研算法验证与模型调试。
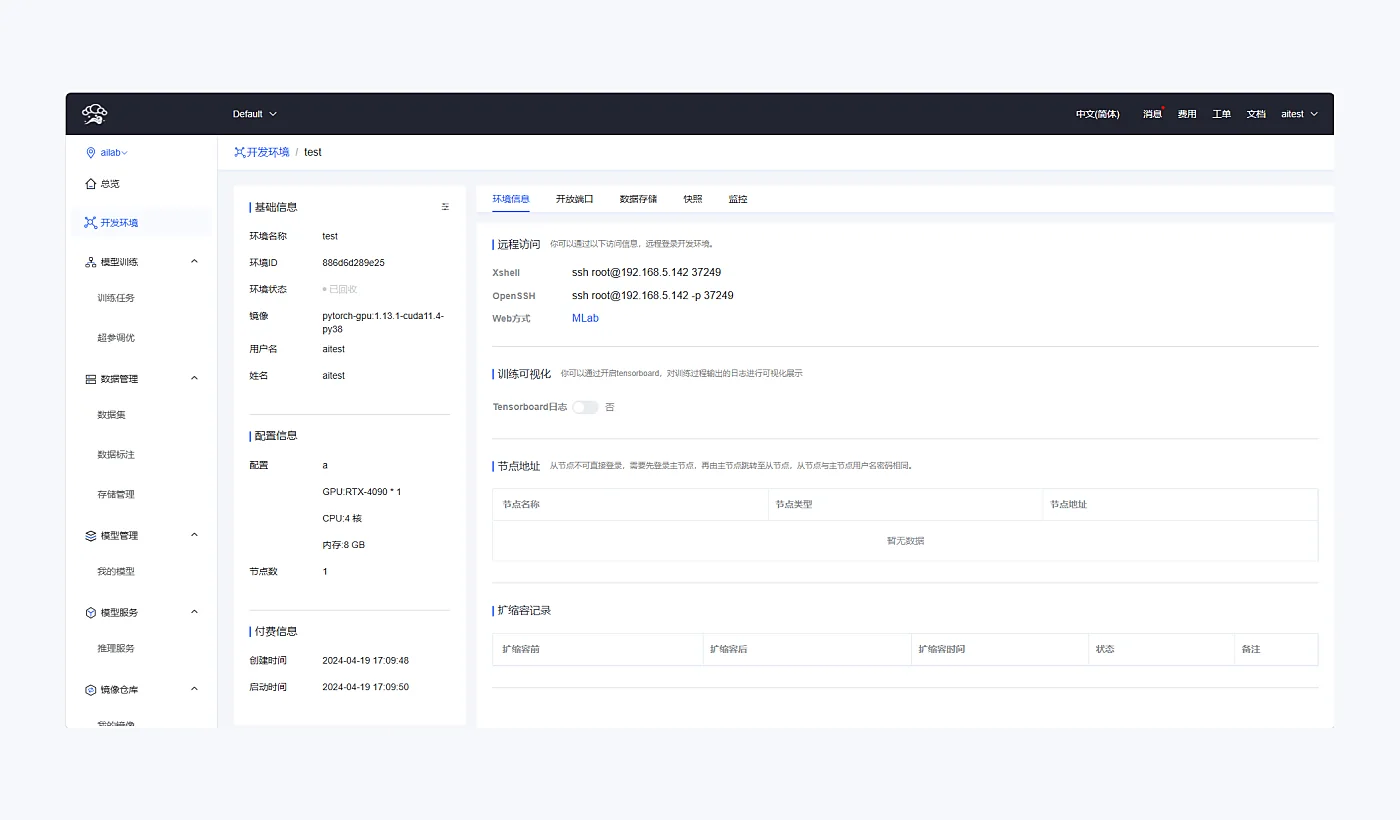
开发环境支持镜像、端口、数据存储、SSH / Web 访问和节点配置统一管理,方便多人按项目进入同一工作流。
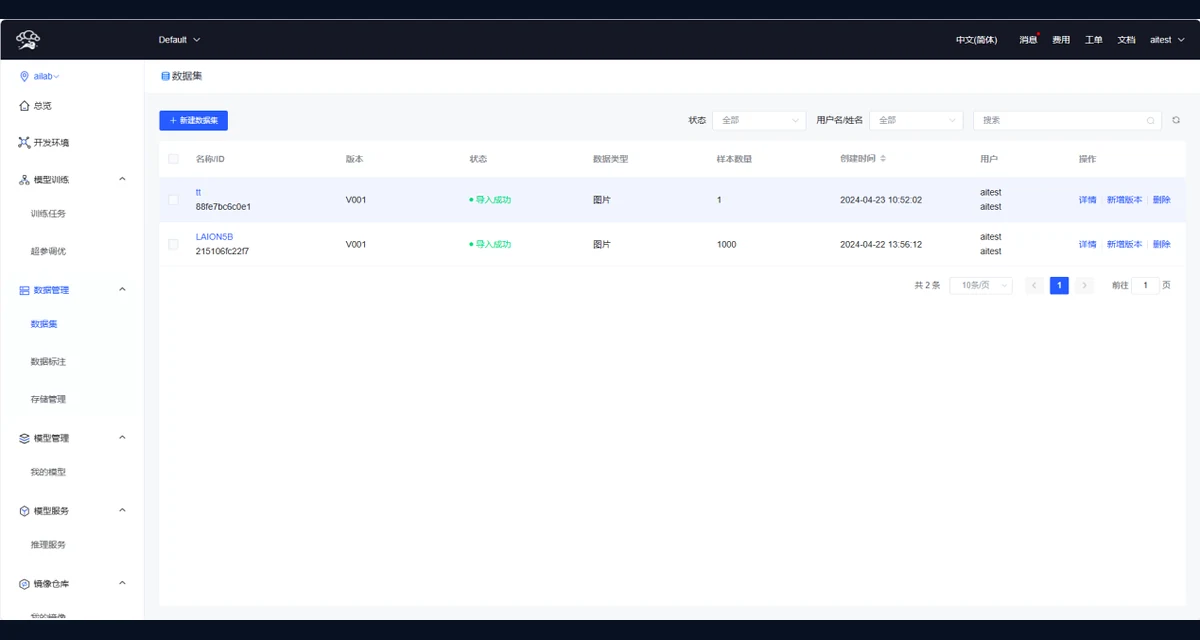
集中管理数据集、数据标注、存储路径和任务输入,便于多项目、多人员协作。
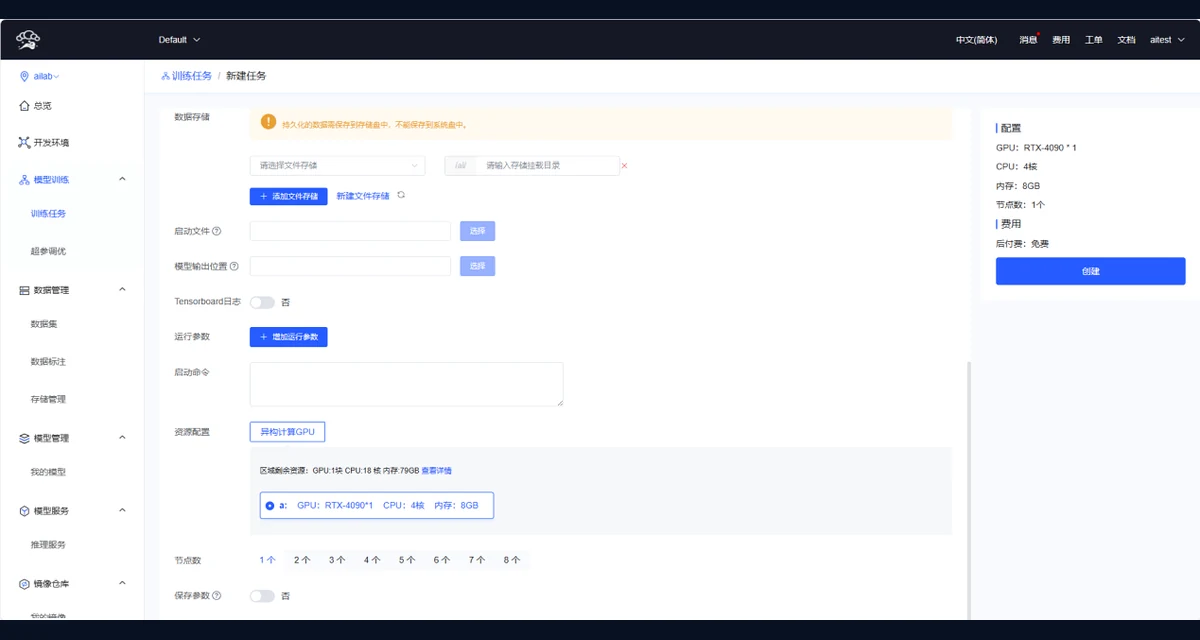
覆盖训练任务、超参调优、资源队列和执行记录,支撑从实验到批量训练的调度流程。
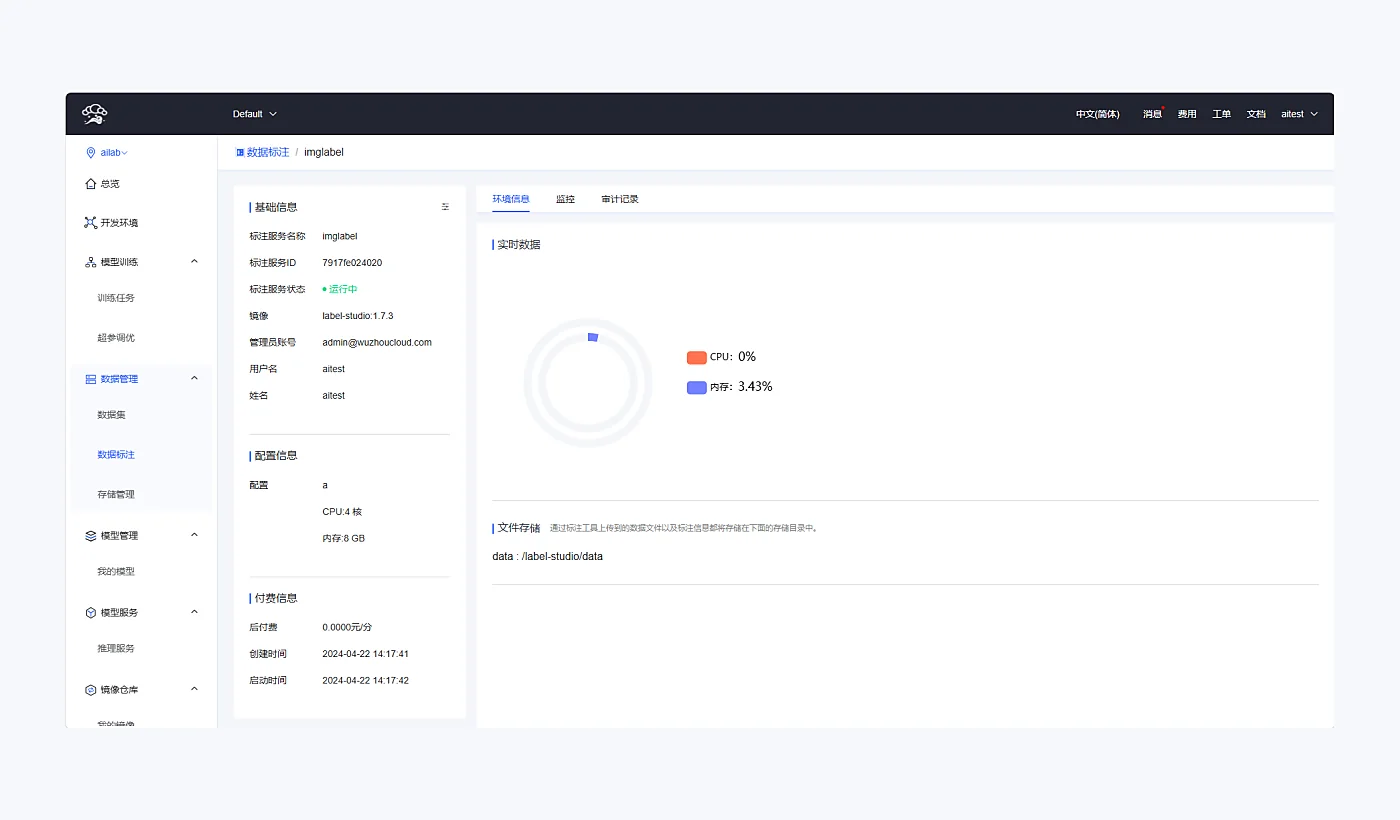
标注服务与运行环境保留实时资源占用视图,便于团队观察 CPU、内存和任务状态。
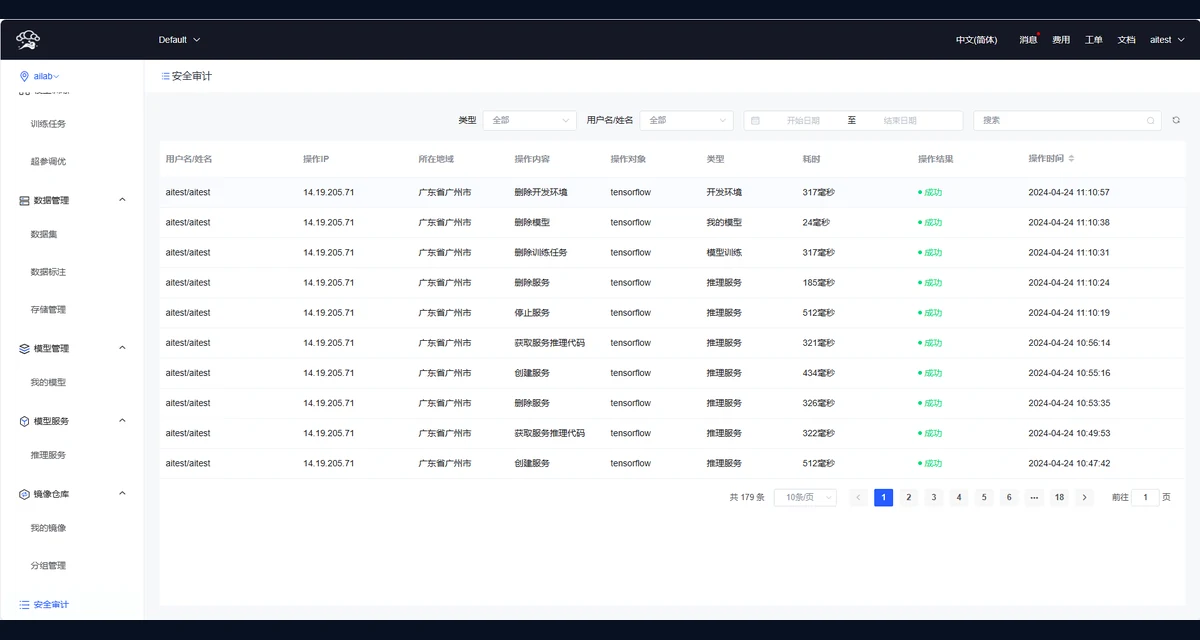
保留代码仓、镜像、任务和模型服务相关操作记录,便于权限管理和追踪复盘。
集成资源监控、模型开发、模型训练、数据管理、模型服务和安全审计的人工智能资源调度与任务管理平台。
这些问题用于帮助你整理任务条件,具体资源、周期和交付深度仍按项目确认。
CPU 更适合大量通用并行计算、批处理和部分传统仿真;GPU 更适合深度学习训练、GPU 加速求解和可视化;NPU 通常用于国产化 AI 训练、推理或适配验证。具体选择需要看软件和任务规模。
不一定。显存不足可能需要降低 batch、使用混合精度、模型切分或更换更大显存卡。增加卡数是否有效取决于训练方式、互联网络和代码并行能力。
资源规格表用于说明可评估的资源类型和配置口径,不等同于实时库存、排队策略或固定交付时间。正式使用前仍需结合任务和当前资源安排确认。
建议准备模型框架、训练脚本、数据规模、预期显存、运行方式和目标结果。如果已有日志或历史运行配置,也可以一起提供,便于判断瓶颈。
多 GPU 服务器长期高负载运行时,散热、电源、机箱空间和噪声会直接影响稳定性。只按显卡型号选型容易忽略整机约束。
可以先评估国产算力适配路径。需要确认模型框架、算子支持、数据格式、目标硬件和推理或训练目标。是否能迁移以及工作量需要按项目验证。