01
算力池按任务组合
CPU、GPU 与国产 NPU 资源统一纳入租用链路,按软件栈、并行方式、显存容量和作业周期匹配资源。
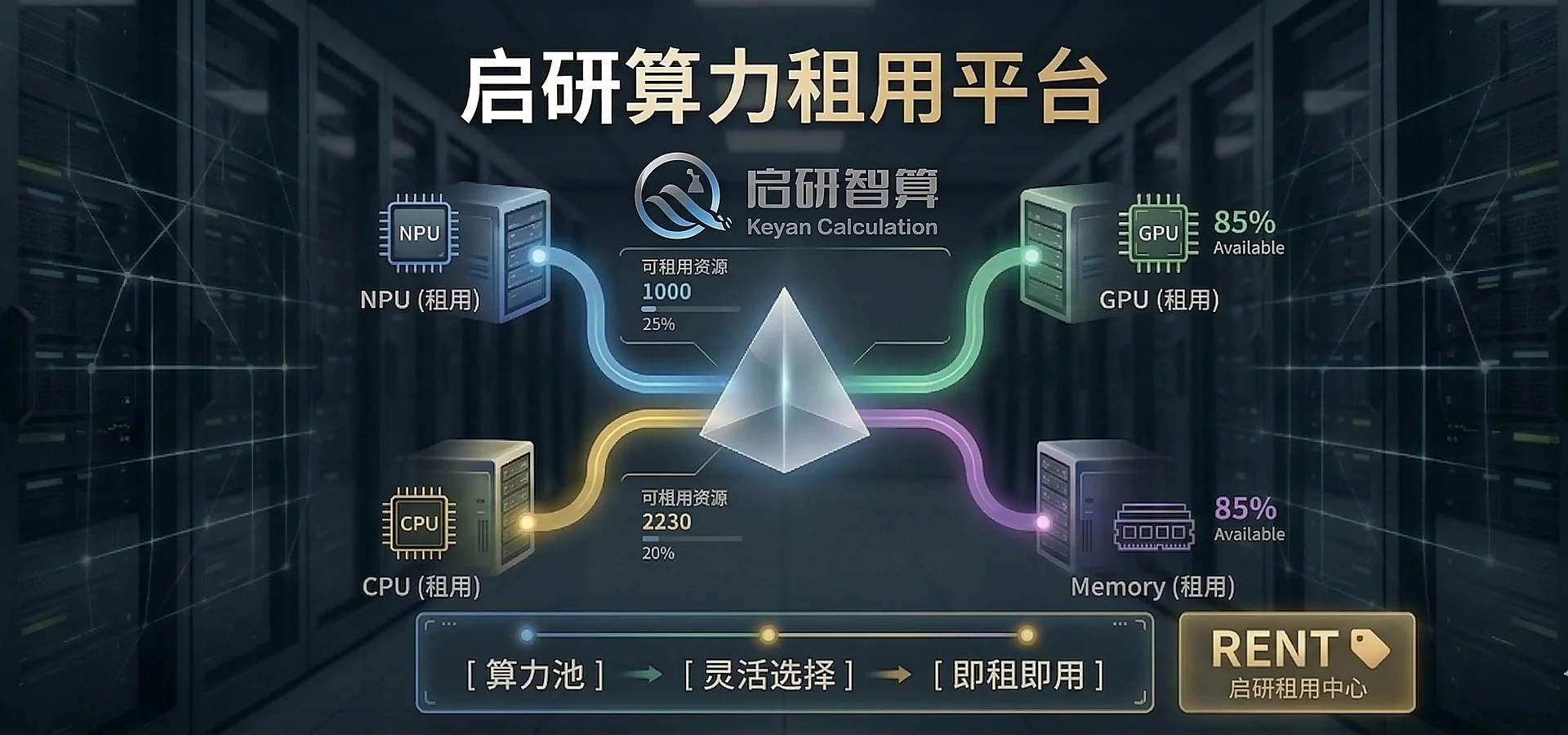
页面先把可选资源按 CPU、国产算力和 GPU 三组展开,咨询时再结合任务规模确认开通方式、队列策略和交付周期。
Intel Xeon / AMD EPYC 多规格节点
华为 Atlas 800T,Ascend 910B x8
RTX 4090 / 3090 / 5090 八卡节点
RoCE / IB 按资源类型接入
适合 VASP、Gaussian、LAMMPS、有限元求解、批量参数扫描等 CPU 密集型科研计算任务。
适合国产化 AI 推理训练、昇腾生态适配和信创环境下的模型任务验证。
适合深度学习训练、推理服务、可视化渲染和 GPU 加速仿真任务。
CPU、GPU 与国产 NPU 资源统一纳入租用链路,按软件栈、并行方式、显存容量和作业周期匹配资源。
咨询后确认账号、镜像、数据目录、队列参数和远程访问方式,适合短期扩容与阶段性项目攻关。
覆盖 VASP、Gaussian、LAMMPS、有限元求解、深度学习训练、推理服务和可视化渲染等常见任务。
按资源类型接入 RoCE / IB 网络,面向大模型训练、轨迹文件读写和仿真结果批量输出保留吞吐空间。
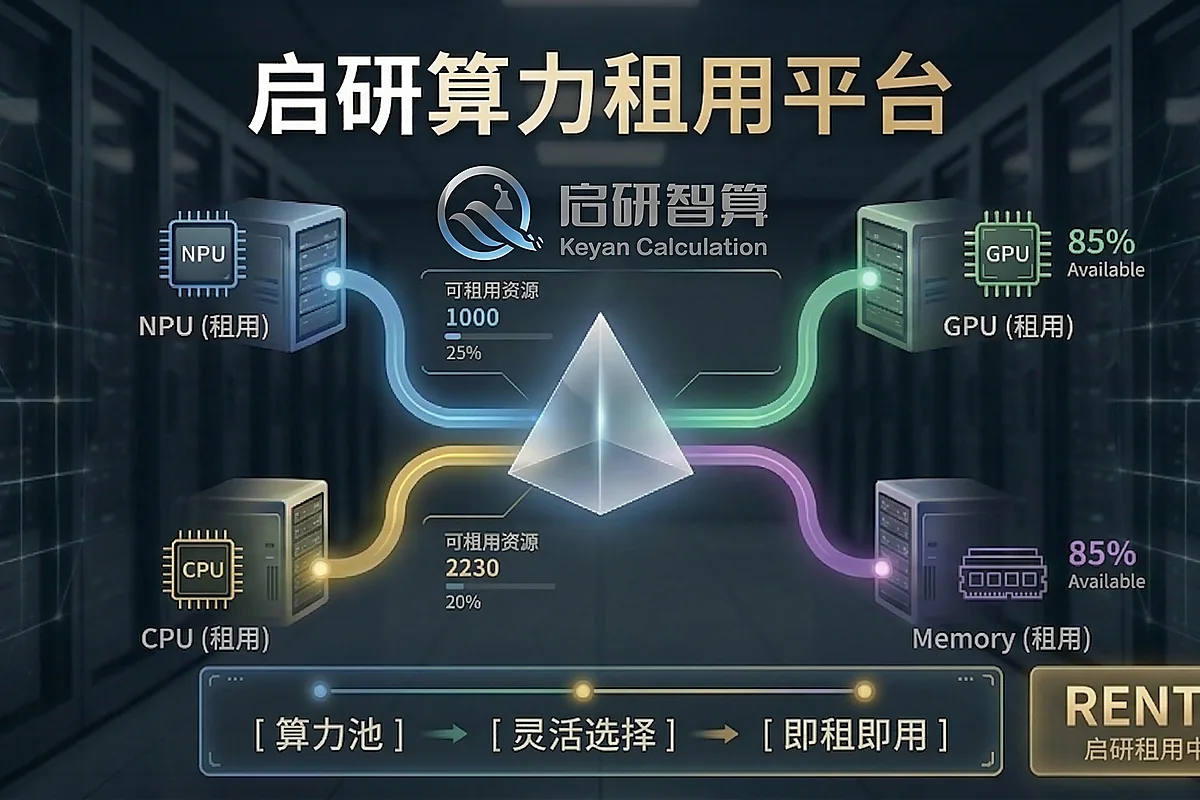
把 CPU、GPU、国产 NPU 与内存、网络等配置放在同一租用语境下,方便用户先判断资源类型,再进入任务评估。
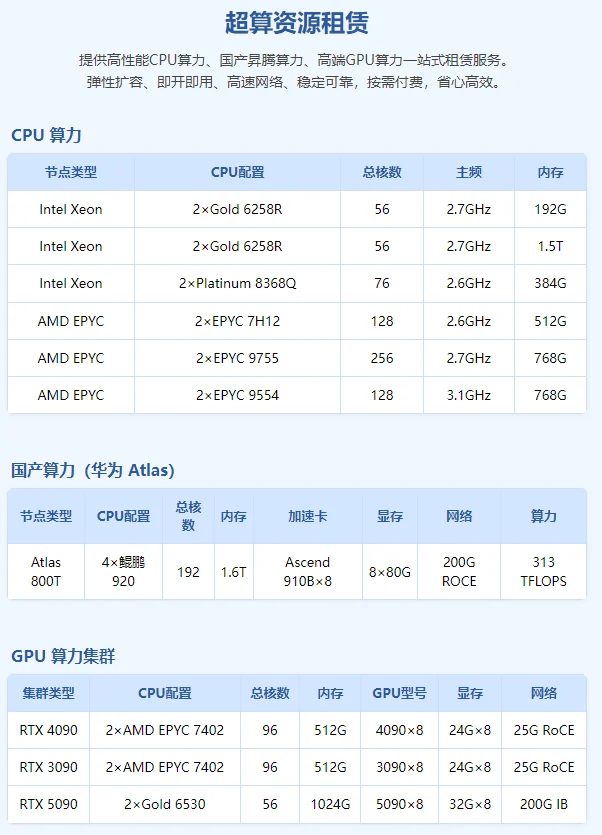
规格信息已转为网页表格展示,图示位置保留原始版式的概览感,帮助用户快速建立资源规模认知。
面向科研计算、AI 训练、仿真模拟、大数据处理和渲染集群等场景,提供弹性灵活的超算算力租赁服务。
这些问题用于帮助你整理任务条件,具体资源、周期和交付深度仍按项目确认。
CPU 更适合大量通用并行计算、批处理和部分传统仿真;GPU 更适合深度学习训练、GPU 加速求解和可视化;NPU 通常用于国产化 AI 训练、推理或适配验证。具体选择需要看软件和任务规模。
不一定。显存不足可能需要降低 batch、使用混合精度、模型切分或更换更大显存卡。增加卡数是否有效取决于训练方式、互联网络和代码并行能力。
资源规格表用于说明可评估的资源类型和配置口径,不等同于实时库存、排队策略或固定交付时间。正式使用前仍需结合任务和当前资源安排确认。
建议准备模型框架、训练脚本、数据规模、预期显存、运行方式和目标结果。如果已有日志或历史运行配置,也可以一起提供,便于判断瓶颈。
多 GPU 服务器长期高负载运行时,散热、电源、机箱空间和噪声会直接影响稳定性。只按显卡型号选型容易忽略整机约束。
可以先评估国产算力适配路径。需要确认模型框架、算子支持、数据格式、目标硬件和推理或训练目标。是否能迁移以及工作量需要按项目验证。